贝叶斯网络实战
- 1. 建立虚拟环境
- 2. 学生是否获得推荐信
- 3. 泰坦尼克数据集预测存活人员
- 参考
1. 建立虚拟环境
conda create -n BayesNN38 python=3.8
conda activate BayesNN38
pip install pgmpy
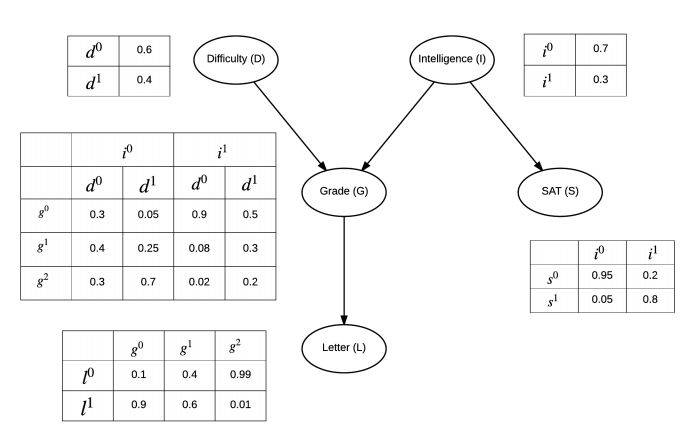
2. 学生是否获得推荐信
代码如下:
from pgmpy.models import BayesianNetwork
from pgmpy.inference import VariableElimination
letter_bn=BayesianNetwork([
('D','G'),('I','G'),('I','S'),('G','L') # 指向关系 D->I
])
from pgmpy.factors.discrete import TabularCPD
d_cpd=TabularCPD(variable='D',variable_card=2,values=[[0.6],[0.4]])
# 变量名,变量取值个数,对应概率
i_cpd=TabularCPD(variable='I',variable_card=2,values=[[0.7],[0.3]])
g_cpd=TabularCPD(variable='G',variable_card=3,values=[[0.3,0.05,0.9,0.5],[0.4,0.25,0.08,0.3],[0.3,0.7,0.02,0.2]],
# 行数等于变量取值,列数等于依赖变量总取值数(3,4)
evidence=['I','D'],evidence_card=[2,2])
# 变量名,变量取值个数,对应概率,依赖变量名,依赖变量取值
s_cpd=TabularCPD(variable='S',variable_card=2,values=[[0.95,0.2],[0.05,0.8]],
evidence=['I'],evidence_card=[2])
l_cpd=TabularCPD(variable='L',variable_card=2,values=[[0.1,0.4,0.99],[0.9,0.6,0.01]],
evidence=['G'],evidence_card=[3]) # evidence_card必须是列表
letter_bn.add_cpds(d_cpd,i_cpd,g_cpd,s_cpd,l_cpd)
letter_bn.check_model() # 检查构建的模型是否合理
letter_bn.get_cpds() # 网络中条件概率依赖关系
print(letter_bn.check_model())
print(letter_bn.get_cpds())
letter_infer=VariableElimination(letter_bn) # 变量消除
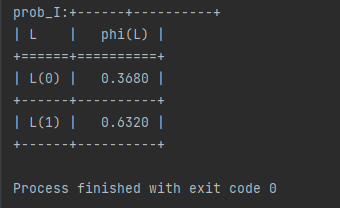
prob_I=letter_infer.query(variables=['L'],evidence={'I':1,'D':1})
print(f"prob_I:{prob_I}")
输出结果:
3. 泰坦尼克数据集预测存活人员
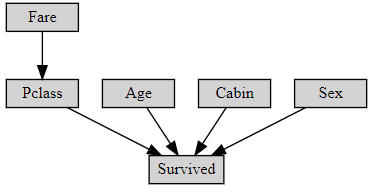
这个数据集是kaggle上一个竞赛数据集,这里使用贝叶斯网络进行预测,贝叶斯网络表示如下图所示:
代码如下:
import pandas as pd
from sklearn.cluster import KMeans
from pgmpy.models import BayesianModel
from pgmpy.estimators import BayesianEstimator
'''
PassengerId => 乘客ID
Pclass => 客舱等级(1/2/3等舱位)
Name => 乘客姓名
Sex => 性别 清洗成male=1 female=0
Age => 年龄 插补后分0,1,2 代表 幼年(0-15) 成年(15-55) 老年(55-)
SibSp => 兄弟姐妹数/配偶数
Parch => 父母数/子女数
Ticket => 船票编号
Fare => 船票价格 经聚类变0 1 2 代表少 多 很多
Cabin => 客舱号 清洗成有无此项,并发现有的生存率高
Embarked => 登船港口 清洗na,填S
'''
# combine train and test set.
train = pd.read_csv('./train.csv')
test = pd.read_csv('./test.csv')
full = pd.concat([train, test], ignore_index=True)
full['Embarked'].fillna('S', inplace=True)
full.Fare.fillna(full[full.Pclass == 3]['Fare'].median(), inplace=True)
full.loc[full.Cabin.notnull(), 'Cabin'] = 1
full.loc[full.Cabin.isnull(), 'Cabin'] = 0
full.loc[full['Sex'] == 'male', 'Sex'] = 1
full.loc[full['Sex'] == 'female', 'Sex'] = 0
full['Title'] = full['Name'].apply(lambda x: x.split(',')[1].split('.')[0].strip())
nn = {'Capt': 'Rareman', 'Col': 'Rareman', 'Don': 'Rareman', 'Dona': 'Rarewoman',
'Dr': 'Rareman', 'Jonkheer': 'Rareman', 'Lady': 'Rarewoman', 'Major': 'Rareman',
'Master': 'Master', 'Miss': 'Miss', 'Mlle': 'Rarewoman', 'Mme': 'Rarewoman',
'Mr': 'Mr', 'Mrs': 'Mrs', 'Ms': 'Rarewoman', 'Rev': 'Mr', 'Sir': 'Rareman',
'the Countess': 'Rarewoman'}
full.Title = full.Title.map(nn)
# assign the female 'Dr' to 'Rarewoman'
full.loc[full.PassengerId == 797, 'Title'] = 'Rarewoman'
full.Age.fillna(999, inplace=True)
def girl(aa):
if (aa.Age != 999) & (aa.Title == 'Miss') & (aa.Age <= 14):
return 'Girl'
elif (aa.Age == 999) & (aa.Title == 'Miss') & (aa.Parch != 0):
return 'Girl'
else:
return aa.Title
full['Title'] = full.apply(girl, axis=1)
Tit = ['Mr', 'Miss', 'Mrs', 'Master', 'Girl', 'Rareman', 'Rarewoman']
for i in Tit:
full.loc[(full.Age == 999) & (full.Title == i), 'Age'] = full.loc[full.Title == i, 'Age'].median()
full.loc[full['Age'] <= 15, 'Age'] = 0
full.loc[(full['Age'] > 15) & (full['Age'] < 55), 'Age'] = 1
full.loc[full['Age'] >= 55, 'Age'] = 2
full['Pclass'] = full['Pclass'] - 1
Fare = full['Fare'].values
Fare = Fare.reshape(-1, 1)
km = KMeans(n_clusters=3).fit(Fare) # 将数据集分为2类
Fare = km.fit_predict(Fare)
full['Fare'] = Fare
full['Fare'] = full['Fare'].astype(int)
full['Age'] = full['Age'].astype(int)
full['Cabin'] = full['Cabin'].astype(int)
full['Pclass'] = full['Pclass'].astype(int)
full['Sex'] = full['Sex'].astype(int)
# full['Survived']=full['Survived'].astype(int)
print(full) # 1308行
dataset = full.drop(columns=['Embarked', 'Name', 'Parch', 'PassengerId', 'SibSp', 'Ticket', 'Title'])
print(dataset) # 1308行
test_data = dataset[891:]
dataset.dropna(inplace=True)
print(dataset) # 891行
dataset['Survived'] = dataset['Survived'].astype(int)
# dataset=pd.concat([dataset, pd.DataFrame(columns=['Pri'])])
train = dataset[:800]
val = dataset[800:]
'''
最后保留如下项目,并切出800的训练集:
Pclass => 客舱等级(0/1/2等舱位)
Sex => 性别 male=1 female=0
Age => 年龄 插补后分0,1,2 代表 幼年(0-15) 成年(15-55) 老年(55-)
Fare => 船票价格 经聚类变0 1 2 代表少 多 很多
Cabin => 客舱号 清洗成有无此项,并发现有的生存率高
'''
#model = BayesianModel([('Age', 'Pri'), ('Sex', 'Pri'),('Pri','Survived'),('Fare','Pclass'),('Pclass','Survived'),('Cabin','Survived')])
model = BayesianModel([('Age', 'Survived'), ('Sex', 'Survived'),('Fare','Pclass'),('Pclass','Survived'),('Cabin','Survived')])
model.fit(train, estimator=BayesianEstimator, prior_type="BDeu") # default equivalent_sample_size=5
# #输出节点信息
# print(model.nodes())
# #输出依赖关系
# print(model.edges())
# #查看某节点概率分布
# print(model.get_cpds('Survived').values)
val_data=val.drop(columns=['Survived'], axis=1)
print(val_data)
y_pred = model.predict(val_data)
val = val.reset_index(drop=True) # 解决以下行索引不同问题
print((y_pred['Survived']==val['Survived']).sum()/len(val))
#测试集精度0.8131868131868132
# 预测test.csv中人员的存活情况
predict_data = test_data.drop(columns=['Survived'], axis=1)
predict_pred = model.predict(predict_data)
predict_pred.to_csv('gender_submission.csv')
这里将竞赛数据集中的训练集分成训练集(train)和验证集(val),竞赛数据集中的测试集作为测试集。输出结果:
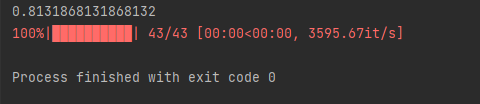
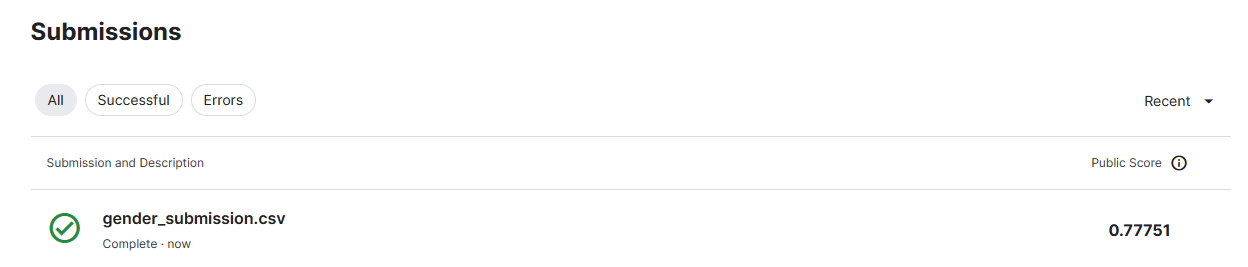
将预测的gender_submission.csv提交到kaggle中,获得了如下所示准确率。
参考
[1] 概率图模型理论与应用–哔哩哔哩
[2] 贝叶斯网络python实战(以泰坦尼克号数据集为例,pgmpy库)–CSDN





![[Rust GUI]eframe(egui框架)代码示例](https://img-blog.csdnimg.cn/8db21b3532e34316a9c3a97bb2649859.png#pic_center)