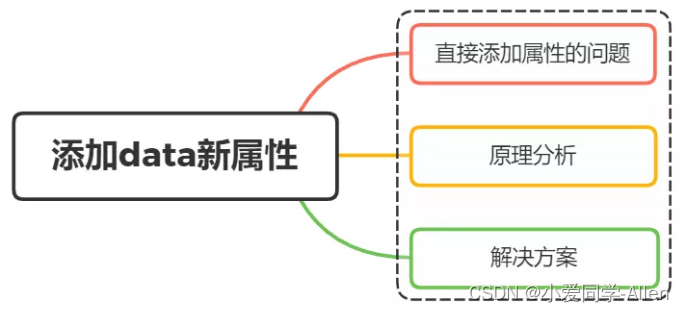
一、概述
监督学习的目标是根据数据进行预测。比如电子邮件垃圾邮件过滤,需要将电子邮件(数据实例)分类为垃圾邮件或非垃圾邮件。
按照传统计算机科学的方法,需要编写一个精心设计的程序,遵循一些规则来确定电子邮件是否是垃圾邮件。尽管这样的程序可能在一段时间内运行得相当好,但它有很大的缺点。随着垃圾邮件的变化,它必须被重写。因为垃圾邮件发送者可能会尝试对软件进行逆向工程并设计绕过它的消息。另外即使程序运行得很好,它也不太容易应用于不同的语言。
机器学习使用不同的方法来生成可以根据数据进行预测的程序。不是手工编程,而是从学习已有的数据得到经验。如果我们有确切知道正确预测的数据实例,那么这个过程就有效。例如,过去的数据可能被用户注释为垃圾邮件或非垃圾邮件。机器学习算法可以利用此类数据来训练分类器,以预测每个带注释的数据实例的正确标签。
二、数学表示
让我们使用数学语言表现监督机器学习。我们的训练数据是成对输入的, 其中
,
是输入实例并且
是它的标签。整个训练数据表示为


![[每周一更]-(第60期):15种MySQL索引失效场景](https://img-blog.csdnimg.cn/d83b7135730245aebd12e005c49e851f.jpeg#pic_center)