目录
一.引言
二.Dataset 生成
1.数据样式
2.批量加载
◆ 主函数调用
◆ 基础变量定义
◆ 多数据集加载
3.数据集合并
◆ Concat
◆ interleave
◆ stopping_strategy
◆ interleave_probs
三.总结
一.引言
LLM 模型基于 transformer 进行训练,需要先生成 dataset,再将 dataset 根据任务需求生成对应的 input_ids、label_ids 等,本文介绍生成 dataset 的方法,即读取多个文件最终生成一个 dataset,后续介绍不同任务需求下 dataset 的转化。
Tips:
本文数据集与代码主要参考 Github LLaMA-Efficient-Tuning。
二.Dataset 生成
1.数据样式
◆ alpaca_data_zh_51k.json

◆ alpaca_gpt4_data_zh.json

数据集为 json 文件,其中每条 json 记录包含 3 个 key:
- instruction 可以理解为 prompt
- input 输入,即我们说的 Question
- output 输出,与 Question 对应的 Answer
上面的 3 个 key也可以简化,前面也提到过 LLM - Baichuan7B Tokenizer 生成训练数据,这里只用了 q、a 两个字段。 这里字段是什么其实并不重要,只要最后生成 input_ids 相关数据可以区分开就可以。
2.批量加载
def getBatchDataSet(_base_path, _data_files, _strategy):
max_samples = 9999
# support multiple datasets
all_datasets: List[Union["Dataset", "IterableDataset"]] = []
for input_path in _data_files:
data_path = EXT2TYPE.get(input_path.split(".")[-1], None)
dataset = load_dataset(
data_path,
data_files=[os.path.join(_base_path, input_path)],
split="train",
cache_dir=None,
streaming=None,
use_auth_token=True
)
if max_samples is not None:
max_samples_temp = min(len(dataset), max_samples)
dataset = dataset.select(range(max_samples_temp))
print(dataset.features)
all_datasets.append(dataset)
if len(all_datasets) == 1:
return all_datasets[0]
elif _strategy == "concat":
return concatenate_datasets(all_datasets)
elif _strategy == "interleave":
# all_exhausted
stopping_strategy = "first_exhausted"
interleave_probs = [0.5, 0.5]
return interleave_datasets(all_datasets, interleave_probs, stopping_strategy=stopping_strategy)
else:
raise ValueError("UnKnown mixing strategy")下面分步骤拆解下代码:
◆ 主函数调用
import os.path
from datasets import load_dataset, concatenate_datasets, interleave_datasets
from typing import TYPE_CHECKING, Any, Dict, Generator, List, Literal, Union, Tuple
from transformers import GPT2Tokenizer
from itertools import chain
import tiktoken
if __name__ == '__main__':
# 多文件地址
base_path = "/Users/LLaMA-Efficient-Tuning-main/data"
data_files = ['alpaca_data_zh_51k.json', 'alpaca_gpt4_data_zh.json']
strategy = 'concat'
train_dataset = getBatchDataSet(base_path, data_files, strategy)这里给定我们需要遍历的两个 json 文件以及对应的合并策略,策略后面再说。
◆ 基础变量定义
EXT2TYPE = {
"csv": "csv",
"json": "json",
"jsonl": "json",
"txt": "text"
}
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
max_samples = 9999
# support multiple datasets
all_datasets: List[Union["Dataset", "IterableDataset"]] = []EXT2TYPE 为文件格式对应的 map,第二个 tokenizer 我们为了演示直接使用 Transformer 自带的 gpt2,max_samples 定义数据集截断,最后的 all_datasets 用于存储多个数据集。
◆ 多数据集加载
for input_path in _data_files:
data_path = EXT2TYPE.get(input_path.split(".")[-1], None)
dataset = load_dataset(
data_path,
data_files=[os.path.join(_base_path, input_path)],
split="train",
cache_dir=None,
streaming=None,
use_auth_token=True
)
if max_samples is not None:
max_samples_temp = min(len(dataset), max_samples)
dataset = dataset.select(range(max_samples_temp))
print(dataset.features)
all_datasets.append(dataset)遍历文件列表的文件与后缀,通过 from datasets import load_dataset 加载声称数据集,max_samples 配合 select 完成数据集的截断,最后将 dataset 添加到 all_datasets 中。这里 dataset.features 类似于 dataframe 的 schema,用于描述每一列的基础信息:
{'instruction': Value(dtype='string', id=None),
'input': Value(dtype='string', id=None),
'output': Value(dtype='string', id=None)}
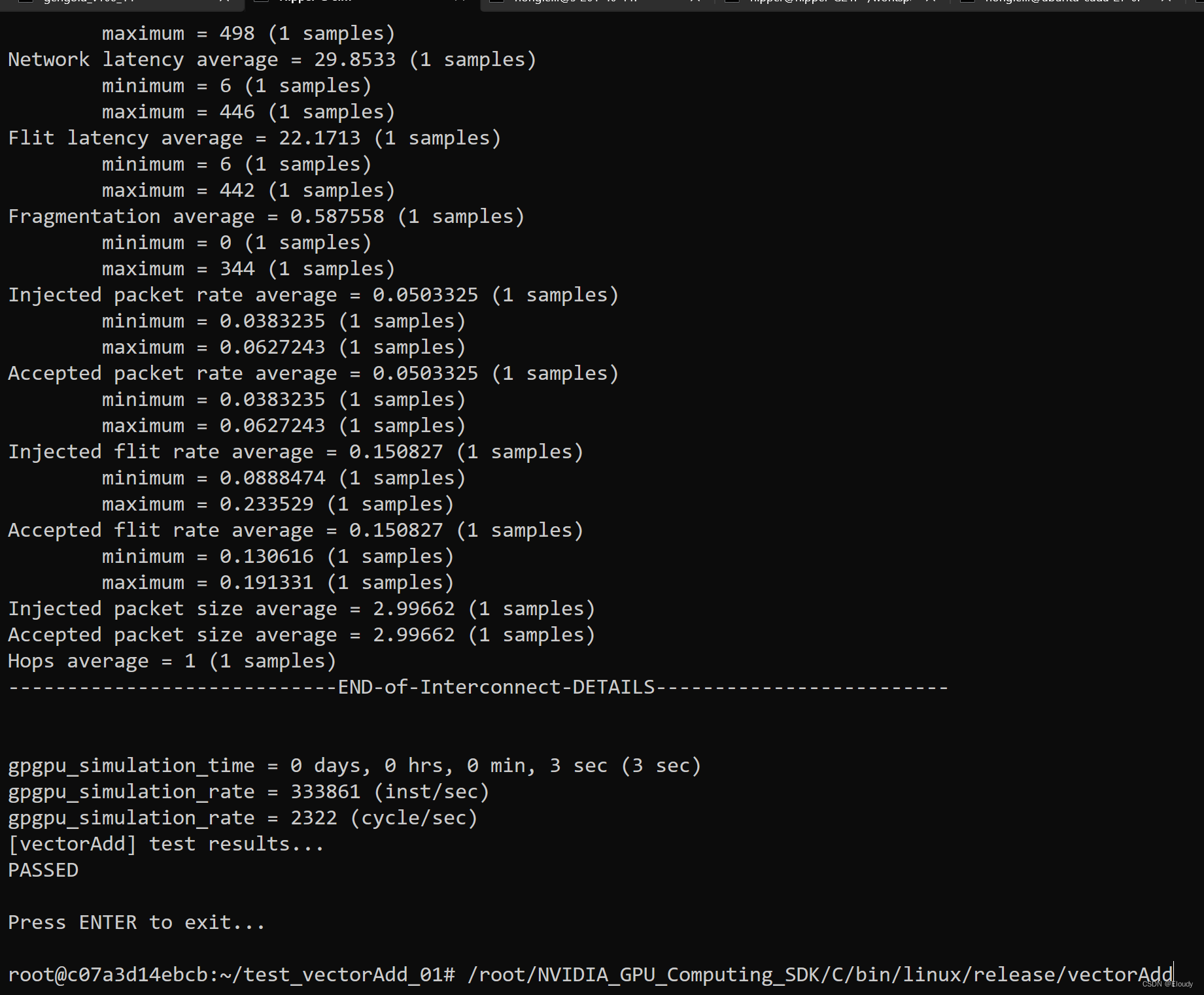
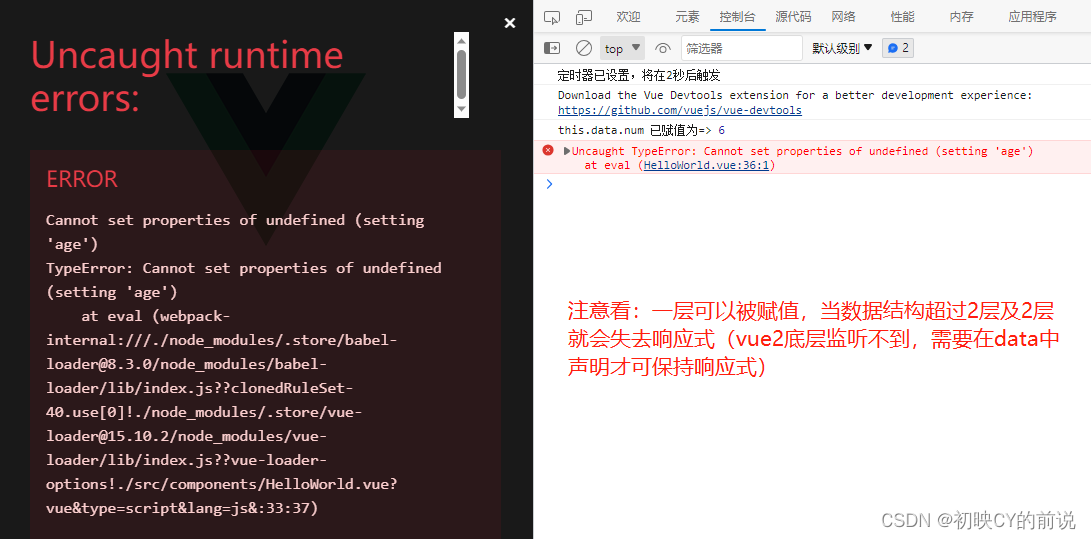
下图为两个数据集记载打印的日志,由于之前已经做了 cache,所以直接读取 arrow 文件:

3.数据集合并
if len(all_datasets) == 1:
return all_datasets[0]
elif _strategy == "concat":
return concatenate_datasets(all_datasets)
elif _strategy == "interleave":
# all_exhausted
stopping_strategy = "first_exhausted"
interleave_probs = [0.5, 0.5]
return interleave_datasets(all_datasets, interleave_probs, stopping_strategy=stopping_strategy)
else:
raise ValueError("UnKnown mixing strategy")由于训练只需要一个 dataset,所以多个文件读取的 dataset 需要合并为一个,上面展示了不同的合并策略,length == 1 的情况就不多说了,除此之外多数据集有两种合并策略:
◆ Concat
cocnat 方法直接顺序拼接多个数据集
dataset-1 => A,B,C
dataset-2 => D,E,F
concat(dataset-1, dataset-2) => A,B,C,D,E,F◆ interleave
interleave 方法用于实现数据交错从而防止过拟合。交错数据集是将两个或更多数据集混合在一起形成一个新的数据集。这样做的目的是使模型在训练时不会总是看到相同的数据顺序,从而提高模型的泛化能力。
dataset-1 => A,B,C
dataset-2 => D,E,F
interleave(dataset-1, dataset-2) => A,E,B,C,D,F◆ stopping_strategy
stopping_strategy 用于定义数据集合并何时停止,有 first_exhausted 和 all_exhausted 两种交错策略:
- first_exhausted (先耗尽策略)
数据集会按照他被添加到 interleave 方法的顺序进行处理,当一个数据集被遍历完会停止生成数据,该方法适用于你希望遍历完第一个数据集就停止迭代。
- all_exhausted (全部耗尽策略)
数据集会按照他被添加到 interleave 方法的顺序进行处理,当全部数据集被遍历完会停止生成数据,该方法适用于你希望遍历完全部数据集就停止迭代。
这两种策略的主要区别在于何时停止迭代并抛出异常。first_exhausted 策略在遍历完第一个数据集后停止,而 all_exhausted 策略在遍历完所有数据集后停止。选择哪种策略取决于你的具体需求和数据集的特性。
◆ interleave_probs
在 interleave_datasets 方法中,interleave_probs 是一个可选参数,用于指定每个数据集的交错概率。当使用 interleave_datasets 方法交错多个数据集时,你可以通过 interleave_probs 参数为每个数据集指定一个概率。这个概率表示在生成交错数据集时,每个数据集被选择的概率。
例如,假设你有两个数据集 A 和 B,并且你设置 interleave_probs=[0.5, 0.5]。这意味着在生成交错数据集时,A 和 B 被选择的概率都是 0.5。
如果你设置 interleave_probs=[0.3, 0.7],则 A 被选择的概率是 0.3,而 B 被选择的概率是 0.7。
这个参数允许你根据需要对不同的数据集进行加权,以便在交错数据集时更倾向于选择某些数据集。
三.总结
LLM 大模型我们大部分时间是调用框架,调用现成模型去微调,熟悉一些工具的使用可以更方便我们在调优的时候对不同部分进行修改,本文主要用于加载原始数据生成 dataset,后续我们基于上面得到的 dataset 生成不同任务所需的数据集。